

AIを導入したのに動かない。PoCはうまくいったのに本番運用に乗らない。その差は、LLMの賢さではなく、その周辺の設計品質にあります。本稿では、PraztoがAIエージェント導入支援の現場で見てきた知見をもとに、業務に効くAIを支える 3つの設計領域 ── 自律/業務接続/決定論 を整理します。LLMが賢くなり続ける一方で、賢いLLMの能力を業務に届けるための設計こそが、いま投資価値のある領域だと考えています。
01 「AIを入れたのに動かない」が起きる理由
「AIを業務に入れたい」というプロジェクトが、ここ数年で爆発的に増えました。一方で、現場では 同じパターンの失敗 が繰り返されています。
- PoCではLLMが見事に質問に答えたのに、本番環境で動かしたら 業務担当者が誰も信頼できない回答 しか返ってこない
- 自律的に判断して動く ── と聞いていたのに、実装を進めるうちに 結局は人間が再入力するパイプ になっている
- 「AIに聞けば何でも答えてくれる」と期待されていたのに、現場では 誰も使わなくなった
こうした失敗の根っこには、共通の誤解があります。「LLMが賢ければAIは業務で動く」 という思い込みです。
しかし実際には、LLM自体の賢さはこの数年で劇的に進化を続けており、それは 競争優位性ではなく前提条件 になりつつあります。差がつくのは、その賢いLLMを 業務にどう接続するか の設計の側です。
02 AIエージェントを支える3つの設計領域
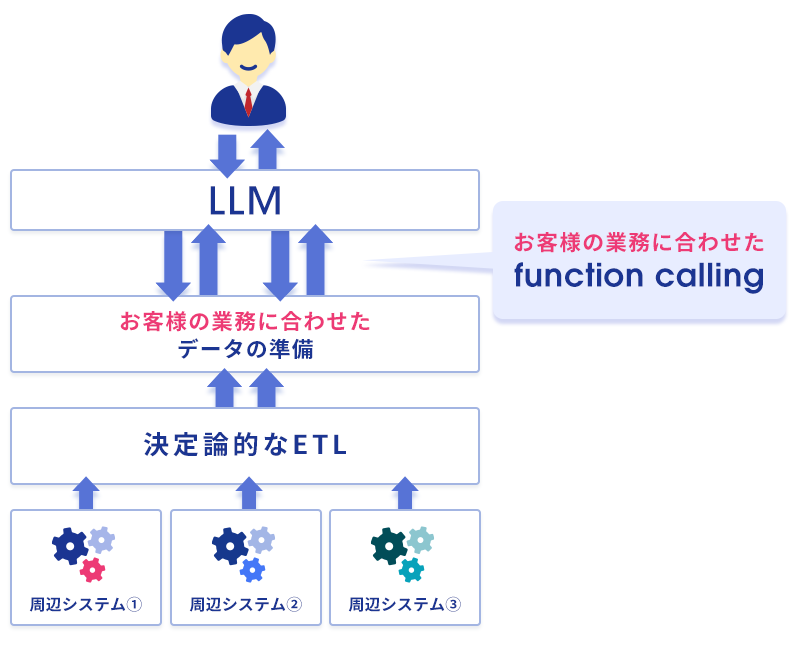
業界では、AIを使った業務システムを語るときに様々な用語が登場します。「Workflow」「Agent」「Tool Use」「Function Calling」── これらは個別に発展してきた概念ですが、業務の現場で実装するときには すべてが一つの構造の中で同時に必要 になります。
Praztoでは、これらを 3つの設計領域 として統合的に整理しています。本稿は、ユーザーがAIに触れる 表層から、根っこのデータ整備へと掘り下げる順序 で、それぞれの領域を見ていきます。
[層1(表層)]自律
LLMが文脈を解釈し、状況に応じて判断する領域。原因仮説の生成、自然言語での対話、文章による示唆 ── ユーザーがAIエージェントに触れる最も表層の窓口です。
[層2(中層)]業務接続
自律領域のLLMが呼び出すFunction群を、業務の意思決定単位に合わせて定義し、業務システムとつなぐ領域。本稿で最も強調したい設計の核心です。
[層3(基底)]データ。およびデータを連携する決定論的ETL
事前に定義された手順を確実に実行し、業務の各システムからデータを正確に吸い上げる基層。AIエージェントが意味のある回答を返すための土台です。ここが整っていないと、上の層がどれだけ良くても機能しません。
表層の自律から始めて、なぜそこに限界があるのか、それを克服するために業務接続が必要で、しかし業務接続も決定論的なデータがなければ機能しない ── という順序で見ていきます。
03 [自律] ── LLMが業務質問に的外れな答えを返す理由
AIエージェントを業務に導入したとき、ユーザーが最初に触れるのは自律領域 ── つまり LLMとの対話 です。質問を投げると、LLMが文脈を解釈し、自然言語で答える。この体験そのものは、ここ数年で劇的に良くなりました。
ところが、実際の業務質問を投げてみると、こんなことが起きます。
よくある現場の声
「『今月の売上着地はどう?』とAIに聞いたら、『一般的に売上着地予測は前年同月比やトレンドで…』 という、教科書的な解説が返ってきた。うちの会社の数字を見て答えてほしいのに。」
あるいはこうです。
- 聞いた質問は具体的なのに、抽象的な一般論しか返ってこない
- 会社名や商品名を言っても、その実態を踏まえずに当たり障りのない回答が返ってくる
- 具体的な数字を返してくるが、その数字の出所が不明で、当てずっぽうのように見える
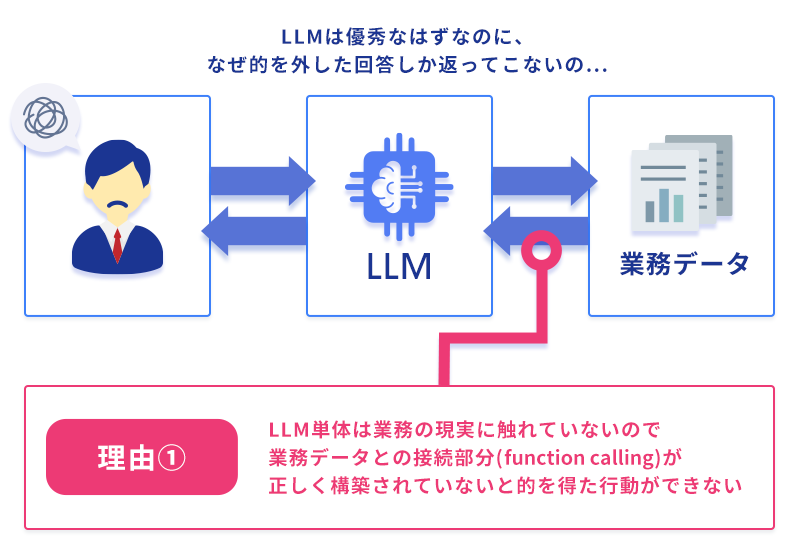
なぜこうなるのか。理由はシンプルで、LLM単体は業務の現実に触れていない からです。LLMは学習した一般知識と、与えられた文脈の範囲でしか推論できません。「うちの会社の売上着地」を答えるには、LLMが うちの会社の業務システムにアクセスして、関連する数字を取り出す手段 を持っていなければなりません。
つまり、自律領域のLLMをいくら賢くしても、業務とつなぐ手段がなければ、業務質問には的外れな答えしか返せない ── これが第一の限界です。
LLM自体の性能は、Anthropic ・OpenAI 等の大手モデルベンダーが世代を重ねるごとに底上げしています。つまり、自律領域は “放っておいても良くなる” 領域です。だからこそ、企業が投資すべきは、自律領域の品質ではなく “自律と業務をつなぐ設計” ── 次の業務接続領域です。
04 [業務接続] ── LLMが呼び出すFunctionの設計
LLMを業務に組み込むための仕組みは、呼称こそ「Tool Use」「Function Calling」などと異なるものの、すでに枠組みとして確立されています。LLMに対して「あなたはこれら一連のFunctionを呼び出せます」とあらかじめ伝えておくと、LLMが状況に応じて適切なFunctionを適切な引数で呼び出してくれる ── というものです。
これによって、LLMは「うちの会社の売上を取得する」「特定の商品の在庫を調べる」「請求書を発行する」といった、業務固有の動作 を自分で組み立てられるようになります。さきほどの「的外れな答え」問題は、業務接続のFunctionが用意されていれば、原理的には解決します。ここで起きる第二の限界
ところが、Tool Use / Function Calling を導入しても、同じ問題が形を変えて再発します。
- LLMが どのFunctionを呼ぶべきか迷う(似たFunctionが多すぎる、定義が曖昧)
- Functionは呼んだが、引数の組み立てを間違える(業務の判断軸とずれた引数設計)
- 呼んだFunctionから 戻ってきたデータが薄っぺらい(必要な切り口が含まれていない)
- 結果として 業務担当者が見て「これは違う」と感じる答え が返る
つまり、Function Callingという枠組みを採用するだけでは不十分で、Functionをどう設計するか が決定的に重要になります。具体的には:
- Functionが 業務の意思決定単位 に合わせて切り出されているか
- Functionの名前と説明文が 業務語彙 で書かれているか
- 引数(Schema)が 業務の判断軸 と一致しているか
- 戻り値が 業務担当者が必要としている粒度・項目 を含んでいるか
同じLLMでも、Functionの定義が業務語彙で精緻に書かれていれば、ユーザーの自然言語質問から適切なFunctionを正しい引数で呼び出せます。逆に、Functionが汎用的・抽象的にしか書かれていなければ、LLMはどれを呼ぶべきか迷い、選択ミスや引数誤りが発生します。
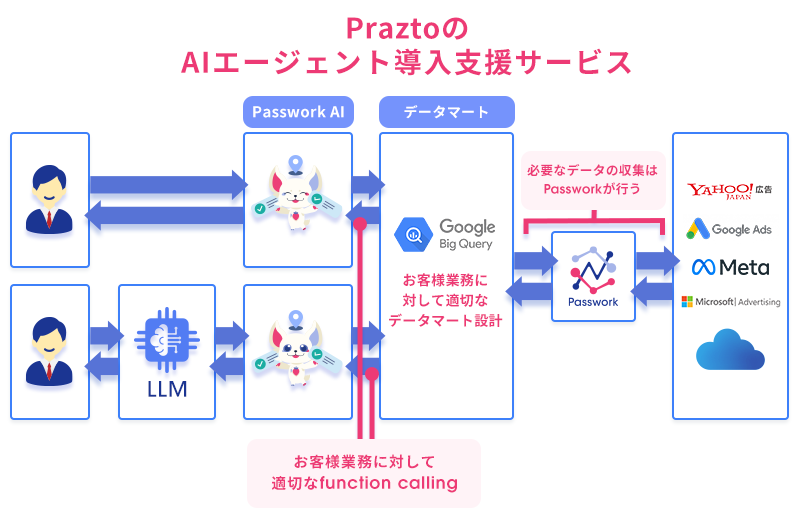
業務接続の設計品質を決めるのは、業務をどれだけ深く理解しているか に他なりません。これは技術スキルだけでは作れず、業務側との対話・要件整理・現場の運用知 を伴って初めて精度高く設計できます。Passwork AI のアプローチ ── 標準実装 × 顧客固有チューニング
Praztoのプロダクト「Passwork AI」では、業界横断で頻出する業務シーン ── 定型的な集計、異常検知、KPI 進捗確認、データ突合・精査 ── に対する Function 群を 標準実装としてあらかじめ用意 しています。これによって、導入直後から一定水準の回答品質が業務担当者に届く状態になります。
一方で、お客様ごとに 業務の判断軸・使われている語彙・データの構造 はそれぞれ違います。同じ「売上」でも、ある会社では受注ベース、別の会社では請求ベース、さらに別では入金ベースで定義されています。同じ「アクティブ顧客」でも、業界・事業フェーズによって定義は揺れます。
ここで重要なのは、Passwork AI は内部の Function Calling 定義そのものを調整できる構造 になっていることです。Function の名前・説明文・引数 Schema・戻り値構造を、お客様固有の業務語彙・判断軸に合わせて作り変えられます。これが、PraztoのAIエージェント導入支援が現場で行うことの大きな柱の 1 つです。標準実装で押さえつつ、要所を顧客固有にチューニングすることで、LLM の選択ミスを減らし、回答の説得力を一段引き上げます。そして、業務接続にも限界がある
Functionをいくら業務語彙で精緻に設計しても、もう一つの限界 にぶつかります。それは:
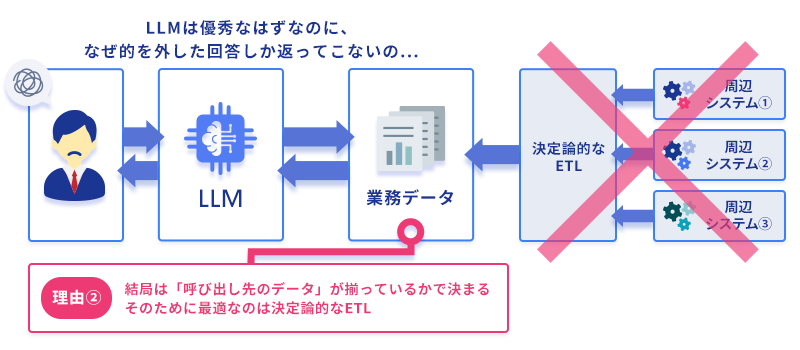
呼び出し先のデータがそもそも揃っていなければ、Functionは何も返せない ── という事実です。
「先月の特定商品の売上推移を見せて」と聞かれたとき、get_product_sales_trend()という素晴らしいFunctionが定義されていても、その関数が触る基幹システム側に該当データが正しい形で存在していなければ、Functionは空の値を返すか、不完全な数字を返すか、エラーを返します。
そして、これが 多くのAIエージェント導入で本当の壁になる ── 第三の限界です。05 [データ] ── 結局は「呼び出し先のデータ」が揃っているかで決まる
業務接続のFunctionが触りに行く先には、必ず 業務システムのデータ があります。Salesforce、基幹システム、各広告媒体、SaaSのAPI、社内DB、Excelファイル ── これらに 必要なデータが、必要な粒度で、必要な構造で揃っている ことが、AIエージェントが業務で機能するための 本当の前提条件 です。
そして、ここで重要な事実があります。このデータ整備はファジーな処理では成立しない ── ということです。なぜ決定論的なETLが効くのか
「LLMにデータも取りに行かせれば良い」という発想は、一見スマートに見えて 実装すると破綻します。
- 同じ質問でも 毎回違うクエリを書く ことになる(再現性ゼロ)
- データの欠損や型の不整合に LLMが弱い(推論で埋めようとして数字が変わる)
- 監査・再現の観点で 「なぜその数字が出たか」を後追い説明できない
- 大量データを毎回LLMで処理する コストとレイテンシが現実的でない
業務でAIエージェントを使うには、決定論的に動くデータパイプラインが必要です。これは新しい仕組みではなく、長年 ETL / iPaaS / RPA などとして発展してきた領域そのものです。Praztoはこの基層を、データ連携プラットフォーム「Passwork」で担っています。
Passworkでは、業務担当者が日本語で要件を記述するだけで、決定論的なデータ連携パイプラインが構築できる設計を採用しており、その思想は 指示書を書くだけで、データ連携(ETL)が完成する世界へで詳しく紹介しています。
具体的には:
- 業務上の 判定ポイント・意思決定ノード に必要なデータを洗い出す(業務側との要件定義)
- 各システム・SaaSから 確実にデータを引き上げる パイプラインを組む
- システムごとに違う形式を 統一スキーマに正規化 する
- 必要な集計・KPI計算を 決定論的に 実装する
- 毎日/毎週/毎月、監査可能な形で データを更新し続ける
地味に見えますが、ここを業務に合わせて精度高く作れているかが、上層のFunction設計、さらにその上の自律領域の回答品質まで、すべてを決定づけます。
表層の「自律領域のLLMが的外れな答えを返す」問題を辿っていくと、中層の業務接続Function設計を経て、最終的には 基層の決定論的データ整備 に行き着きます。AIエージェントの精度は、根っこのデータ品質を超えられない ── これが現場で繰り返し検証されてきた事実です。06 実例:広告運用AIエージェントの中身
ここまでの議論を、Praztoが提供している 広告運用AIエージェントの実装で具体的に見ていきます。広告運用は、業務のファネルポイント(成果が判定される購買・成約までの各段階)が明確に定義しやすい業務であり、3つの設計領域がどう協働するかを示すのに適した題材です。
シーン:朝9時、CPA急騰アラートが届くまで
運用担当者が朝出社すると、Slackに以下のような通知が届いています。
このアラートが届くまでの流れを、3つの設計領域に分解するとこうなります。

"朝 09:00"
"データおよび決定論的ETL"
・ETL : Google Ads / Meta / Yahoo / LINE / TikTok の API から前日データを取得
・データマート化 :
広告運用のファネルポイント(インプレッション → クリック → CV)に紐付けてKPI計算
閾値判定「CPAが前日比 +52%」を検知
"業務接続 : function calling"
・LLMに渡されたFunction群の中から、原因仮説の検証Functionを順次呼び出し
①CPCのSPikeの判定function
→ 戻り値:CPC ¥100 → ¥150(+50%)、過去14日中央値比 +49%、急騰判定 = true
②競合圧力の判定fucntion
→ 戻り値:Impression Share 82% → 61%、Auction Insights で新規競合2社の出現、競合圧力 = high
③繁忙期の判定function
→ 戻り値:例年同時期 CPC 平均 +35%、業界キーワード検索量 +45%、繁忙期入り = true
④クリエイティブ疲弊の判定function
→ 戻り値:CTR / CVR / Frequency いずれも平常範囲、疲弊判定 = false
"自律 : LLM"
・LLMが文脈を解釈:
「CPC急騰が主因。クリエイティブ疲弊・計測異常はなし。Impression Share低下と新規競合の出現、
業界検索量と過去同時期の傾向から、繁忙期入り+競合激化による外部要因の CPC 高騰と判定。
内部要因ではないため、戦術的な配分シフトで対応を推奨」
SlackにLLMの解釈を通知する以下のように表現するとわかりやすいかと思います。
- データおよび決定論的ETL
- 必要な広告データが、日次で正確に保存されていないと正しく分析できない。
- お客様業務に合わせて、適切なファネルポイントでKPIとして集計されていないと異常値判定できない。
- 業務接続 : function calling
- 「CPCのSPikeの判定」「競合圧力の判定」「繁忙期の判定」などのfunctionが、お客様業務および集計データに正しく定義されていないと、LLMが正しく処理を行えない。
もし基層の決定論的データ整備が雑だったら ── たとえば正しいファネルポイントで集計値とKPIを持っていなければ、LLMは「異常かどうか」を統計的に語ることができません。もし業務接続のFunctionが「全部入りの汎用 query」だけだったら、LLMはどう問い合わせれば良いか迷い、確実な数値根拠を伴った応答にはなりません。3層が揃って初めて、賢いLLMの能力が業務担当者に届きます。
07 AIが「正しく答えられる」ための条件
ここまで見てきた議論を整理すると、AIエージェントが業務担当者の質問に正しく答えられるかどうかは、2つの土台 によって決まることが見えてきます。
①お客様の業務に合わせた、業務接続のFunction群
LLMが呼び出すFunctionが、業務の意思決定単位ごとに切り出され、業務語彙で書かれ、戻り値が業務担当者の判断軸を満たす構造になっていること。Function設計の精度が、LLMの選択ミスを減らし、回答の説得力を担保します。
②業務の判定ポイントを捉えた、決定論的なデータ整備
業務上の判定・意思決定ポイントを特定し、そこに必要なデータを抜け漏れなく、正規化された状態で取り込めていること。AIエージェントは “業務の輪郭” が見える形で整えられたデータの上でしか、意味のある推論を組み立てられません。
この2つが揃って初めて、自律領域のLLMはその性能を最大限に発揮できます。逆に言えば、LLMをどれだけ高性能なものに替えても、この2つが弱ければAIエージェントは業務に届きません。
そして注目すべきは、この2つの土台はどちらも “自動的には良くならない” 領域だということです。LLM自体は世代交代で勝手に良くなりますが、業務接続のFunction設計と決定論的なデータ整備は、少なくともしばらくは、適切な業務理解と要件整理を伴う 人の仕事 でしか作れません。

08 Praztoが向き合う領域 ── 業務接続とデータ整備の伴走
Praztoは、AIエージェント導入支援において、業務接続のFunction設計と、その下の決定論的データ整備 を主戦場としています。LLM自体の進化は業界全体に任せるとして、その能力を業務に届けるための 周辺設計 にこそ、伴走の価値があると考えています。
- 業務担当者・意思決定者へのヒアリングを通じた 業務上の判定ポイント・意思決定ノードの明確化
- 各業務システム・SaaSから 確実にデータを吸い上げるパイプラインの設計と実装(プロダクト「Passwork」が担う)
- 業務語彙で精緻に書かれたFunction群 の設計と実装、LLMへの提供
- 本番運用での Function呼び出しの監査・改善、業務との整合性チェック
350社以上のシステム実装で積み上げてきた業務理解と、データ連携プラットフォーム「Passwork」を組み合わせることで、決定論的なデータ整備から業務接続のFunction設計、そして本番運用までを一気通貫で支援します。これがあって初めて、いまのAIが業務で活きる ── 私たちはそう考えています。
「自社の業務にAIをどう入れるべきか分からない」「PoCは動いたが本番に乗せられない」「LLMベンダーを選定する前に、業務側の準備が何なのか整理したい」── そうした段階の議論からでも、Praztoの AIエージェント導入支援サービス ではご相談を受けています。


