基幹システムのデータを元にした離反客に対して、HubSpotを使ったマーケティングを行いたい。なぜそれが難しいか。
飲食店向けに食材や消耗品を提供するビジネスにおいて、顧客の継続的な購買は非常に重要です。特に、一度取引を開始した顧客が徐々に購入頻度を下げたり、いつの間にか取引が途絶えてしまうというケースは珍しくありません。このような「離反傾向にある顧客」や「すでに離反してしまった顧客」に対して、適切なタイミングでコミュニケーションを取り、関係を修復することは売上回復のための重要な施策です。
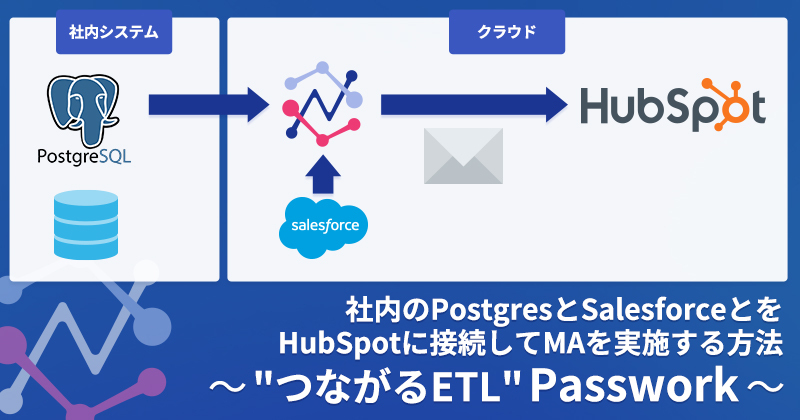
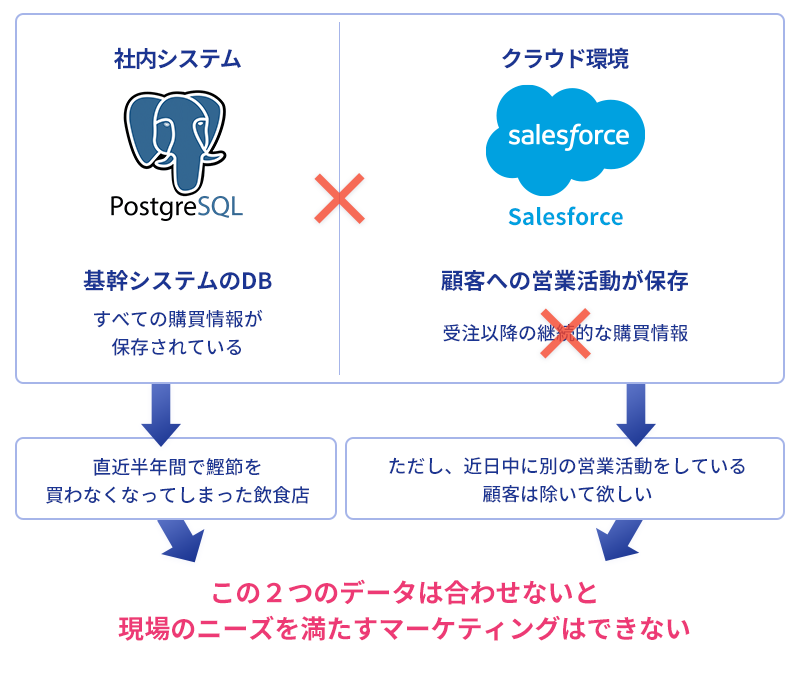
例えば、鰹節などの消耗品を飲食店に販売している企業を考えてみましょう。この企業様では、以下のようなシステム構成で業務が運用されているとします。
- 社内のPostgres
- 顧客と鰹節などの消耗品の注文履歴が保存されています。受注以降の販売情報はここでしか管理されていないため、顧客の継続的な購買状況はこのデータベースから把握する必要があります。
- Salesforce
- 見込み客から受注までのプロセスを管理しています。主に新規顧客獲得までのプロセスをトラッキングしていますが、受注後の継続的な購買情報は管理していません。
- HubSpot
- マーケティングオートメーション(MA)を実施するためのプラットフォームとして活用されています。
理想的には、これらのシステムに分散しているデータを統合して分析し、以下のようなターゲット選定を行いたいと考えます。
- 直近半年間で鰹節を買わなくなってしまった飲食店
- ただし現在別の提案活動を行なっているお客様は除く
この一見シンプルに思えるマーケティング施策の実現には、いくつかの大きな技術的課題があります。本記事では、これらの課題と、Praztoが提供するETLサービス「Passwork」を活用した解決策について詳しく解説していきます。
難しい点① 社内システムとクラウドとの分離について
上記のようなマーケティング施策を実施する上での最初の障壁は、「社内システムとクラウドサービスの分離」という問題です。
多くの企業では、基幹システムやデータベースはセキュリティ上の理由から社内ネットワーク内に配置されています。一方、SalesforceやHubSpotなどのSaaSは当然ながらクラウド上に存在します。この2つの環境は分離されており、簡単に連携させることができません。
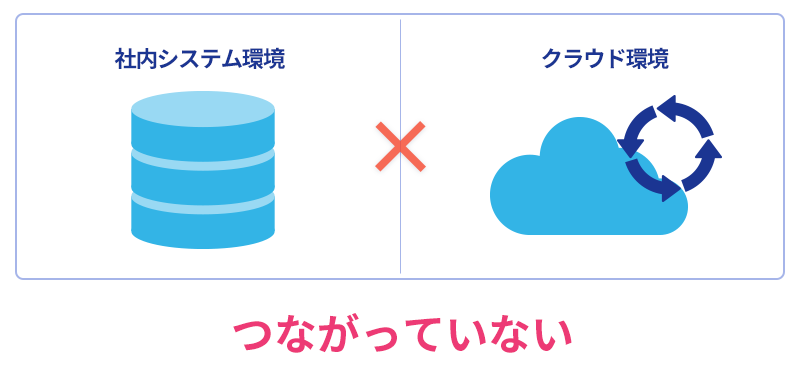
この「社内システムとクラウドの分離」という課題に対しては、通常はシステム開発会社に依頼して専用の連携システムを構築するか、社内に専門知識を持った人材を抱える必要があります。しかし、どちらの選択肢も、コストや時間の面で大きな負担となることが多いのが現実です。
難しい点② 現場で要求される複雑な条件指定
社内システムとクラウドサービスの連携が技術的に可能になったとしても、次に立ちはだかるのは「複雑な条件指定」という課題です。マーケティング施策は単純なデータ抽出では不十分で、ビジネスの文脈に沿った複雑な条件指定が必要になります。
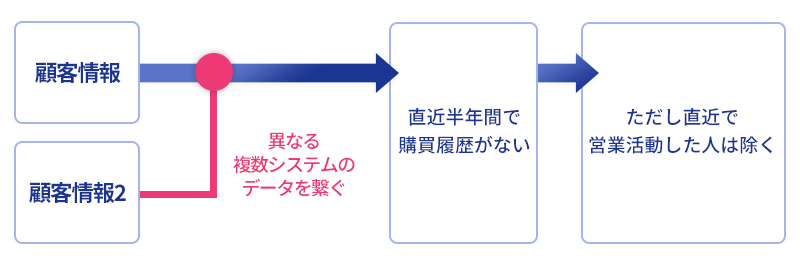
例えば、今回のケースでは以下のような複雑な条件設定が必要になります。
- 時系列での購買行動分析:
- 「直近半年間で購入がない顧客」を特定するには、現在の日付から6ヶ月前までの期間に注文がない顧客を抽出する必要があります。
- 複数システム間でのデータ結合:
- 社内Postgresから取得した離反傾向のある顧客リストと、Salesforceから取得した顧客とを突き合わせる必要があります。
- 動的な条件変更への対応:
- マーケティング施策の効果検証や市場状況の変化に応じて、「半年間」という期間を「3ヶ月間」に変更したり、「購入量減少」の判定基準を調整したりする柔軟性も求められます。
- これらの変更が生じるたびにシステム開発者に依頼する必要があると、迅速な施策変更が困難になります。
- 例外処理の実装:
- ビジネスの現場では、「特定の大口顧客はこのキャンペーンから除外したい」「特定地域の顧客には別のアプローチをしたい」など、様々な例外的な条件が発生します。
- これらの例外処理をシステムに組み込むことは、コーディングなしでは難しい課題です。
これらの課題を解決するには、ビジネスの文脈を理解した上で、複雑な条件設定を直感的なインターフェースで実現できるツールが必要です。次章では、Passworkがこれらの課題をどのように解決するのかを詳しく見ていきます。
Passworkでどのようにして解決するか。
前章まで、社内のPostgresデータベースとSalesforce、HubSpotを連携させたマーケティング施策を実施する上での2つの主な課題について解説しました。ここからは、PraztoのETLサービス「Passwork」がこれらの課題をどのように解決するのかを具体的に見ていきましょう。
Passworkは、異なるシステム間のデータ連携を「ノーコード」で実現するETL(Extract, Transform, Load)サービスです。その名前の通り、様々なシステムを「パスワーク」のように繋ぎ合わせ、シームレスなデータフローを実現します。
Passworkが提供する主な価値は以下の2点です:
- VPN接続による社内システムとクラウドの安全な接続:
- PassworkのProfessional Plan以上であれば、お客様の社内システムとPassworkクラウド環境とVPNで安全に接続することが可能です。
- ノーコードでの複雑なデータ処理の実現:
- 直感的なインターフェースを通じて、複雑なデータ結合やフィルタリング、変換処理をプログラミングなしで設定できます。
- ビジネスユーザーが自らデータフローを設計・変更できるため、IT部門への依存度を大幅に軽減します。
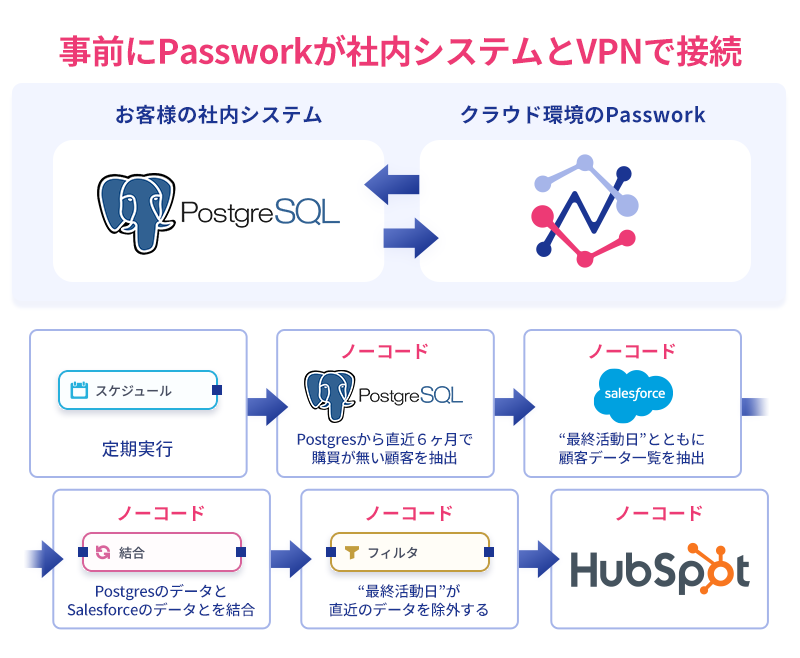
鰹節などを販売する企業のケースに当てはめると、Passworkを活用することで以下のようなワークフローが実現可能になります。
- 社内のPostgresデータベースから、直近6ヶ月間の購買データに存在しない顧客を抽出
- Salesforceから別のセールス部署が管理する顧客データのうち、最終活動日が6ヶ月以上前のデータを抽出
- 1と2のデータを結合して、Emailが未設定などの不正なデータを除外
- 最終的なターゲットリストをHubSpotに送信し、適切なマーケティングキャンペーンを実行
このワークフローを一度設定すれば、その後は定期的に自動実行することも可能です。例えば、毎月1日に自動的にデータを更新し、離反リスクのある顧客に対して適切なタイミングでアプローチすることができます。
以下では、Passworkの2つの主要機能について、より詳細に解説していきます。
特徴① VPN接続による、Passworkと社内システムとの接続
Passworkの特徴の一つが、Professional Plan以上での社内システムとPassworkとのVPNでの接続する機能です。この機能により、お客様が社内で管理をしているPostgresと直接Passworkが繋がることができるようになります。

特徴② わかりやすく力強い連携機能
もうひとつのPassworkの大きな特徴が、直感的でわかりやすいPassworkの連携機能になります。


実際に今回のケースがどのように設定できるかを検証してみましょう。
【手順①】各種システムに接続する 〜 コネクタの作成 〜
最終的には先ほど説明したフローを構築しますが、まずは各システムへの接続をあらかじめ設定しておきます。今回はPostgres、Salesforce、HubSpotへの接続が必要です。

画面左上の「新規作成する」ボタンをクリックすることで、新しいコネクタを作成できます。
コネクタの作成が完了したら、認証情報を登録します。下記のような画面から簡単な操作で登録することができます。
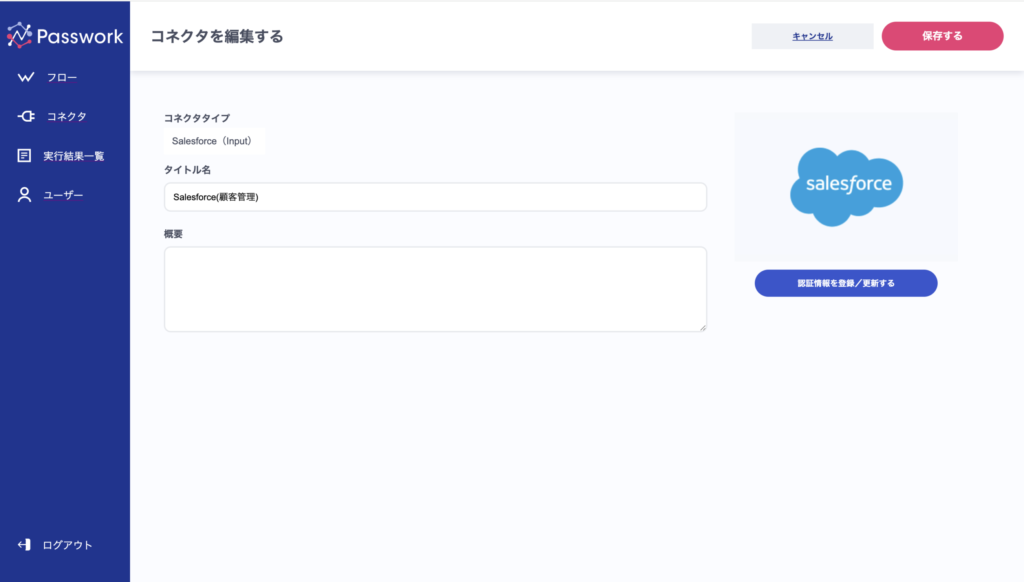
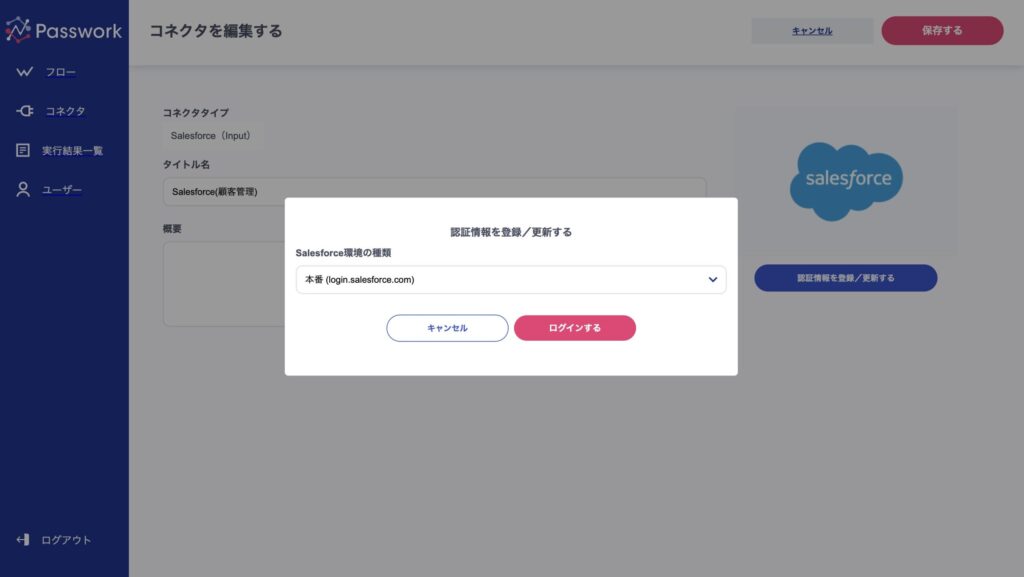
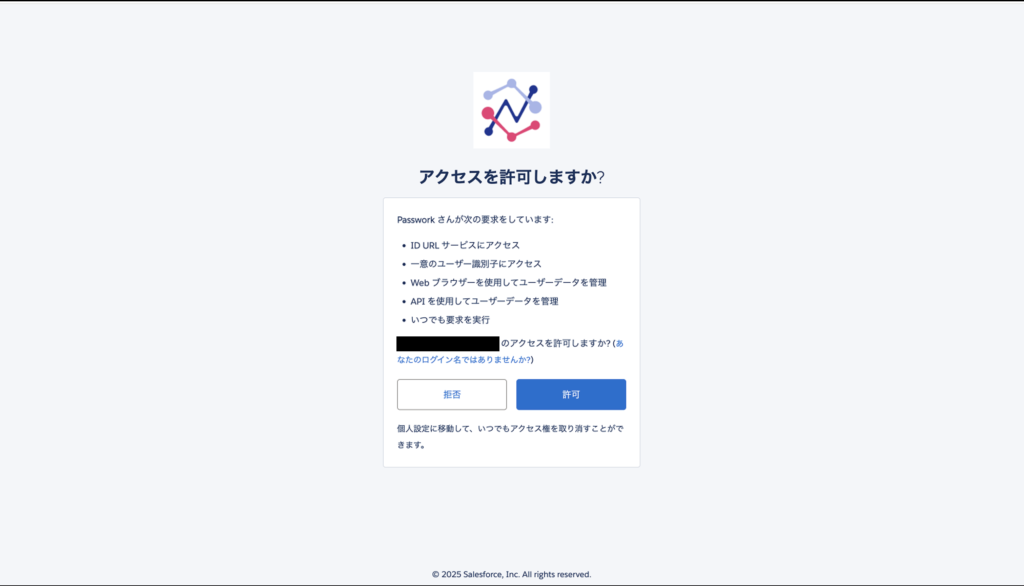
【手順②】フローの設定を行う 〜 データの取得 〜
続けてフローの構築を行っていきます。まずはデータの取得から始めます。
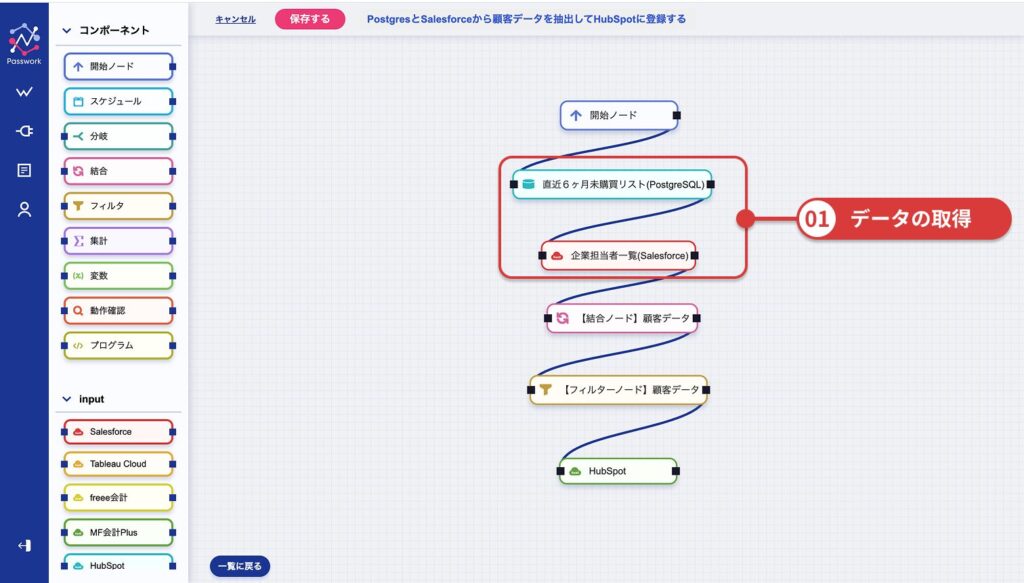
最初にPostgresからのデータ取得設定を編集します。
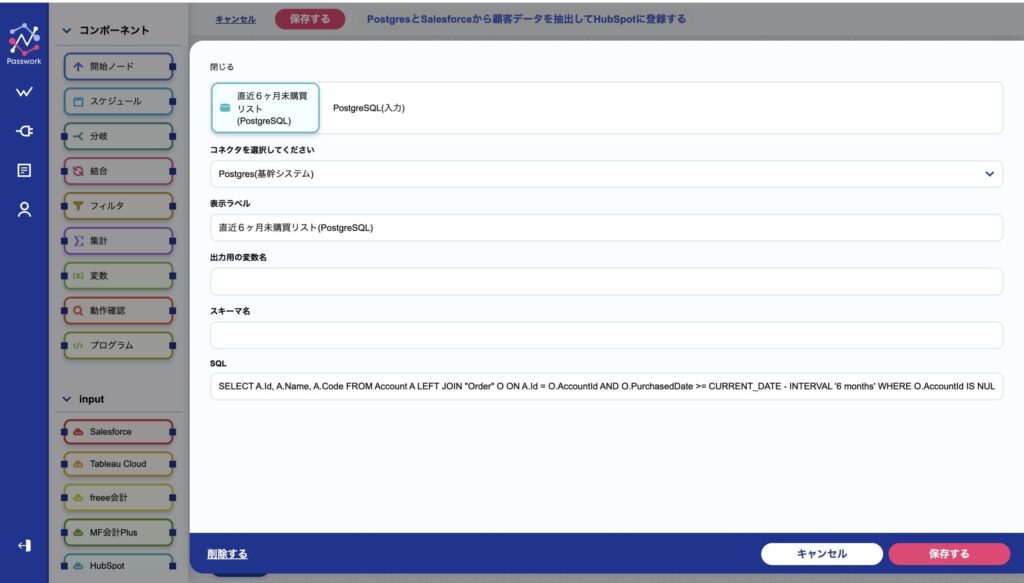
画面上のノードをクリックするだけで、直感的に条件を設定することができます。
- 上部で、事前に設定したPostgresコネクタを選択します。
- 下部で、SQL文を入力します。
これにより、Postgresから「直近6ヶ月未購買リスト」の取得設定が完了しました。
次にSalesforceからのデータ取得について設定します。
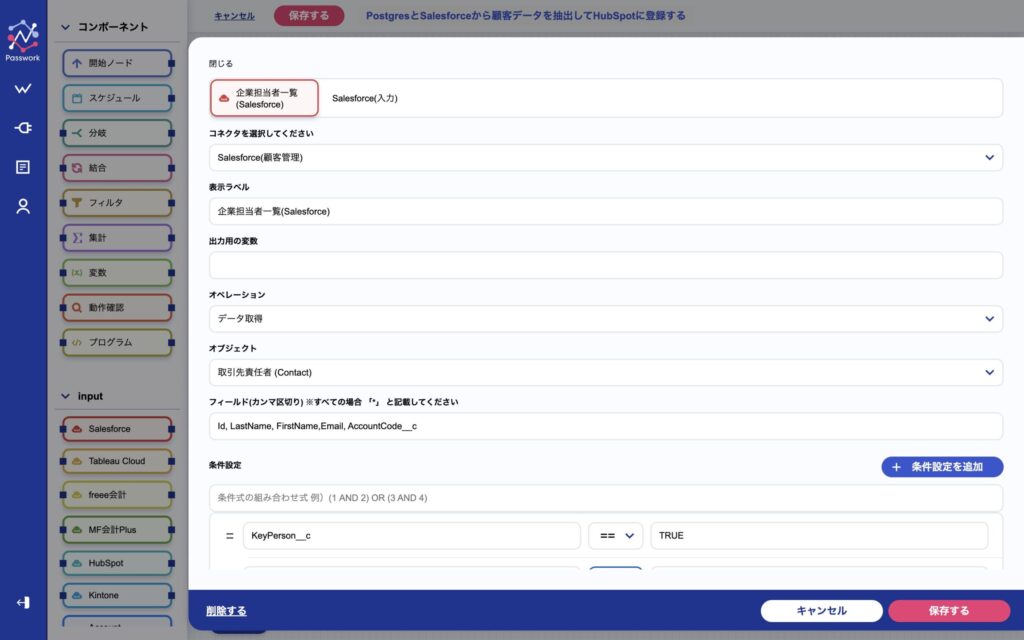
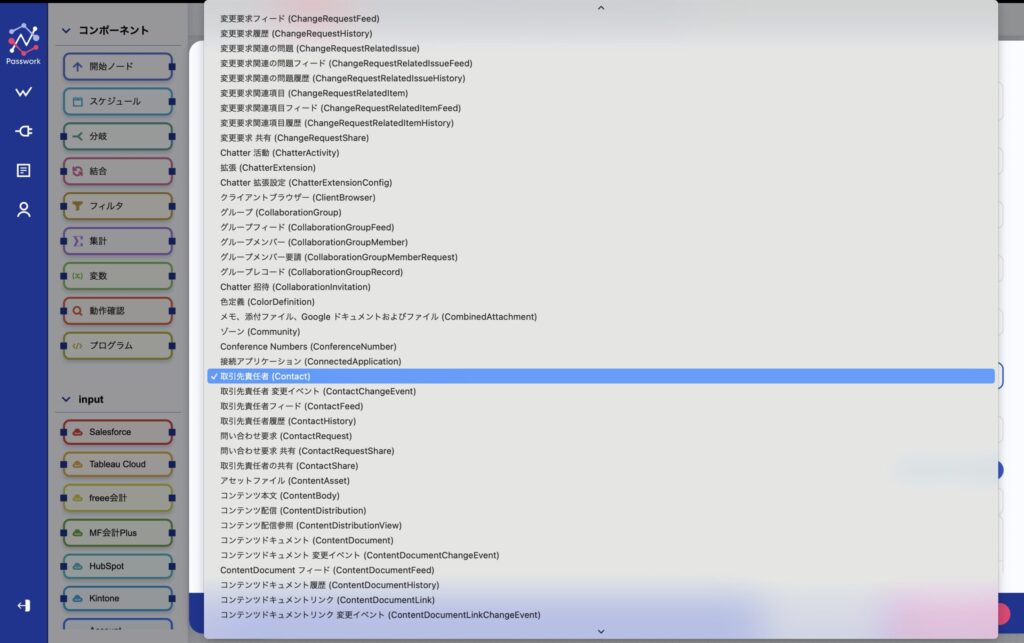
画面上部で事前に設定したSalesforceコネクタを選択し、取得対象のオブジェクトを選択します。取得対象のオブジェクトは、Salesforce組織に設定されているものが自動的に選択リストに表示されるため、直感的に選ぶことができます。
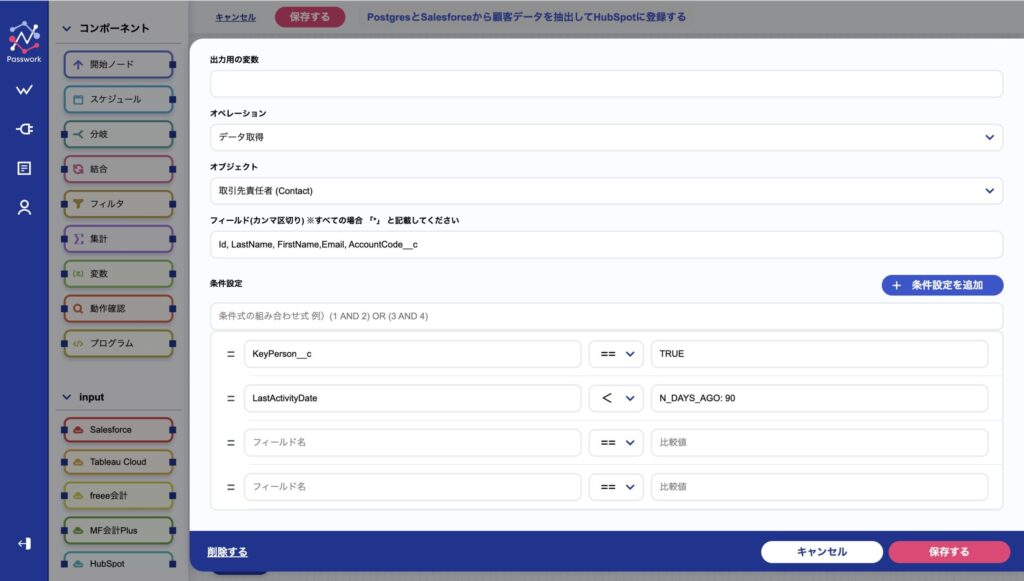
画面の下部では、取得する取引先責任者の条件を指定しています。今回の設定では、キーマンであり、直近90日間活動がない人に限定しています。
【手順③】フローの設定を行う 〜 データの結合や整形 〜
続けて、取得したデータをフロー上で結合し、必要なデータだけに絞り込んでいきます。
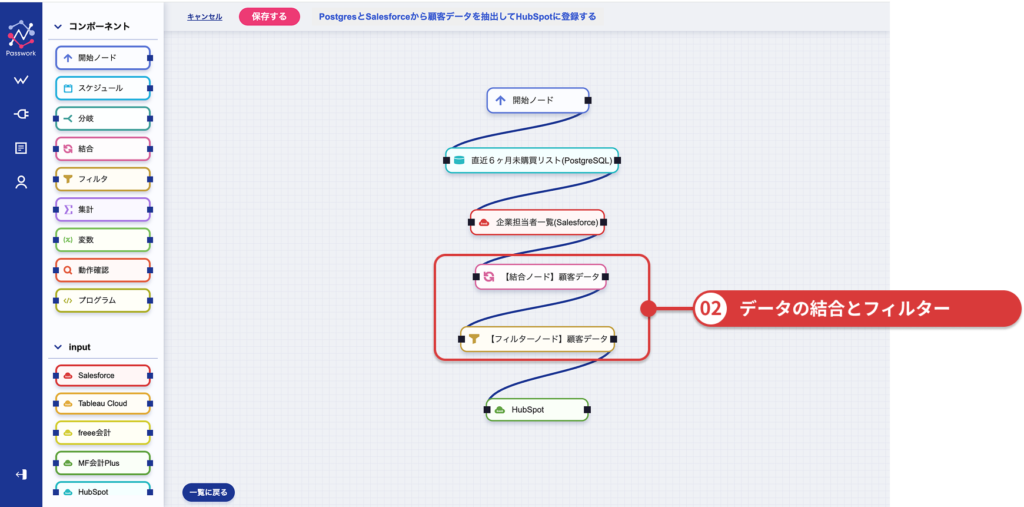
まずはデータの結合から行います。
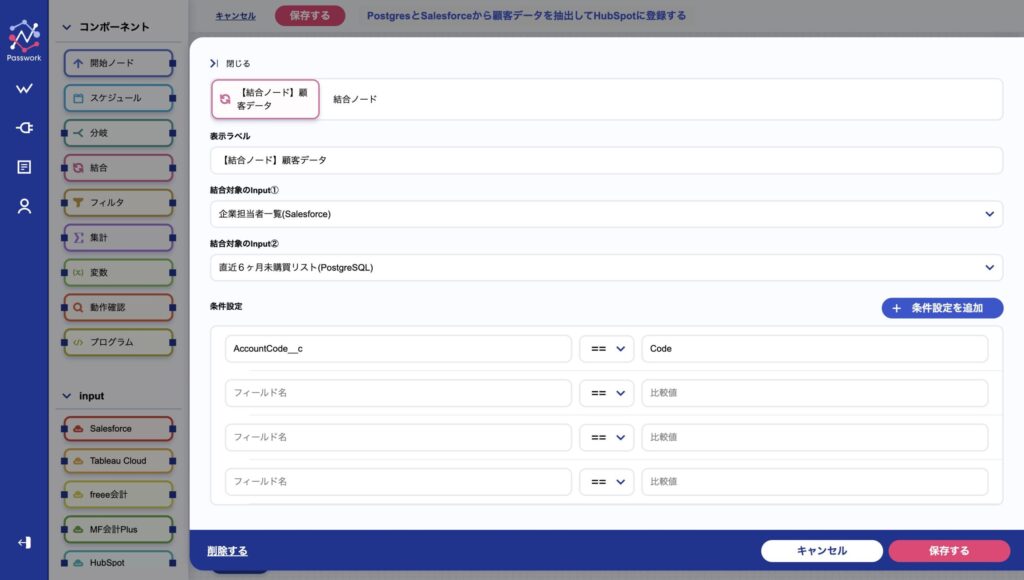
結合ノードをクリックすると、どのInputとInputを結合するかの設定画面が表示されます。先ほどノードとして設定した、PostgresのデータとSalesforceのデータを選択し、画面下部で結合条件を設定します。
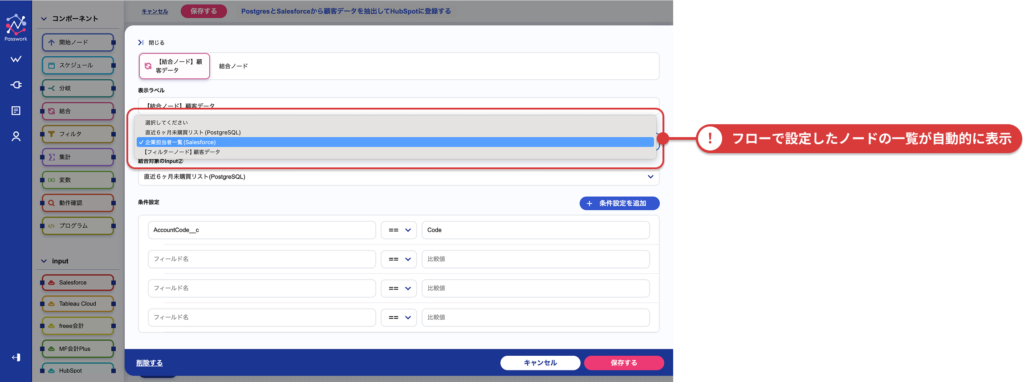
対象となるノードが自動的に選択リストに表示されるため、直感的な操作で設定できます。
同様に、フィルターノードの設定も行います。
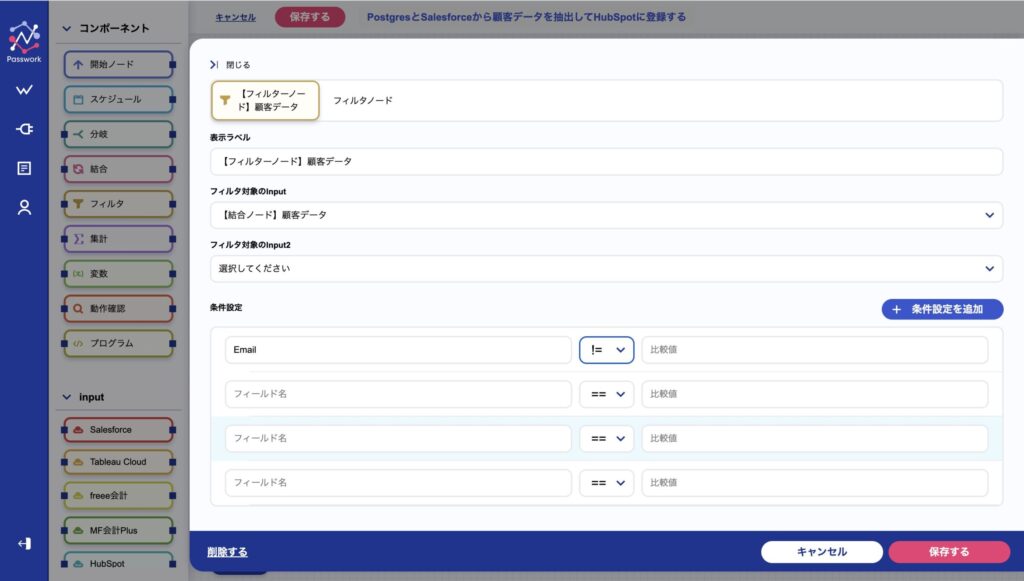
最終的にHubSpotに連携する前に、Emailのデータが空白になっているレコードを除外しています。
【手順④】結合・フィルタしたデータをHubSpotに連携
ここまでの流れで、社内システムにあるPostgresから購買データを取得し、Salesforceに保存されている顧客データとを結合して、整形を行いました。
このデータをHubSpotに連携することで、今回の目的としていたデータ連携が完成します。
HubSpotへの登録方法については、近日中に公開するブログでご紹介しますので、ぜひお楽しみにしてください!
【まとめ】現場で要求されるデータ連携と、Passworkでの解決策
今回は、実際の運用現場で求められるデータ連携とはどのようなもので、なぜ既存のサービスでは対応が難しいのかについてご説明しました。
- 社内システムとクラウド型SaaSにデータが分散して保存されている
- 異なるシステムのデータを結合し、フィルタや整形をしなければならない
また、これらの課題を解決するコンセプトで作られたPassworkの機能をご紹介させていただきました。
- 【機能①】VPNを使用した、社内システムとクラウド型SaaSとのデータ連携にも対応したEAI・ETL
- 【機能②】直感的な操作で、強力なデータ加工ができる編集画面
ご興味がある方は、ぜひ弊社までお問い合わせください!